
Come funzionano le IA che ci scrivono

Utilizzare chatbot IA sta diventando talmente frequente che sta rimpiazzando di pari passo la ricerca sul web classica così come la conoscevamo. Chiediamo a un’IA di cercare sul web, spiegarci qualcosa che non conosciamo, scriverci il riassunto di un testo, risolvere un compito scolastico, una poesia in rima o un consiglio per la cena, e quella risponde in italiano fluente e creativo. A volte sembra di parlare con un piccolo scrittore artificiale dalla fantasia infinita. Ma come fa, davvero, a generare queste risposte? Sta pensando e capendo la domanda come farebbe una persona? Risposta veloce: No. E capire come funziona sul serio un LLM – acronimo di Large Language Model, ovvero modello linguistico di grandi dimensioni – è importante per sfatare alcuni miti e usarlo al meglio.
Questo articolo proverà a fare chiarezza, semplificando, su cosa avviene dietro le quinte quando una di queste IA elabora una domanda e produce una risposta. Con esempi semplici (anche fiabeschi!) vedremo passo passo come è fatto internamente un LLM, come funziona e come genera testo, toccando concetti chiave e termini come tokenizzazione, embedding e trasformatori. Scopriremo inoltre perché un LLM, per quanto sofisticato, non è una mente cosciente né infallibile, e come conoscere la sua struttura ci aiuta a usarlo in modo più consapevole, apprezzandone le potenzialità senza dimenticarne i limiti.
Come funziona un LLM: dall’input alla risposta
Immaginiamo di chiedere a un modello come ChatGPT qualcosa di creativo. Ad esempio: “C’era una volta un regno incantato dove viveva un giovane drago. Un giorno…” e gli domandiamo di continuare la storia. In pochi secondi l’LLM produce magari un racconto avvincente, pieno di avventure. Cosa è successo, in termini semplici, dentro il “cervello” artificiale del modello? Ecco le fasi principali del processo:
- Comprensione del prompt (input): il testo della nostra richiesta viene prima preparato in modo che il modello possa lavorarci. In pratica l’LLM spezzetta la frase in unità più piccole chiamate token (parole o frammenti di parole) e le converte in numeri. È un po’ come tradurre la frase in un linguaggio matematico che la macchina possa elaborare.
- Analisi del contesto: a questo punto i token numerici vengono passati attraverso la rete neurale del modello. L’LLM esamina il contesto della frase e, sulla base di ciò che “ha imparato” da miliardi di parole di training, stima quale potrebbe essere la parola (o token) più probabile dopo quelle già date. In questa fase interviene il meccanismo di attenzione tipico dei trasformatori: il modello valuta in parallelo tutti i termini presenti nel prompt e assegna più peso a quelli più rilevanti, ignorando quelli meno significativi. In altre parole, “capisce” quali concetti chiave sono emersi finora (es. regno incantato, giovane drago) e li usa per predire come la storia potrebbe proseguire.
- Previsione della prossima parola: in base all’analisi, l’LLM produce una sorta di elenco di possibili continuazioni, ciascuna con una certa probabilità statistica. Ad esempio, dopo la frase “C’era una volta un giovane drago” il modello potrebbe calcolare che il token “che” ha il 40% di probabilità di venire dopo, “dragone” il 15%, “di” il 10%, “principe” il 5%, e così via – a seconda di ciò che ha appreso dai testi durante l’addestramento. In effetti, l’LLM non inventa dal nulla la continuazione: sta scegliendo la parola successiva basandosi sui pattern linguistici che ha già visto moltissime volte.
- Generazione iterativa della risposta: una volta ottenute le probabilità, il modello sceglie un token come prossimo elemento della risposta. Spesso seleziona quello con la probabilità più alta, ma può introdurre un po’ di casualità per rendere il testo meno prevedibile. Immaginiamo che scelga ad esempio “che”. A questo punto il token “che” viene aggiunto alla frase generata e il modello ripete nuovamente il passo 2: rianalizza tutto il contesto aggiornato (“C’era una volta un giovane drago che”) e calcola il token successivo. Poi di nuovo e così via, parola dopo parola, fino a completare la frase o il paragrafo richiesto. Questo processo a catena continua finché l’LLM produce un segnale di fine risposta (ad esempio un token speciale di stop) oppure finché raggiunge un limite di lunghezza prestabilito.
Possiamo paragonare il tutto a un super-autocompletamento intelligente: come quando il telefono ci suggerisce le parole mentre digitiamo un messaggio, ma in questo caso con una potenza e una base di conoscenza immensamente più grandi. L’LLM, addestrato su innumerevoli esempi di frasi, prevede di volta in volta il pezzo mancante successivo, cucendo insieme una risposta frase dopo frase.
🔍 Token ed embedding: l’alfabeto segreto
Un computer non “comprende” realmente le parole testuali: deve rappresentarle con dei numeri. La tokenizzazione è il procedimento che converte il testo in piccoli segmenti (token) che possono essere elaborati dal modello. Spesso i token corrispondono a parole intere, ma possono anche essere sillabe o addirittura singole lettere nei casi complessi. Ad ogni token l’LLM associa poi un embedding, ovvero un vettore di numeri (di solito decine o centinaia di valori) che rappresenta quella parola in forma matematica all’interno dello spazio “mentale” del modello. L’idea è che parole con significato o uso simile avranno vettori (embedding) simili tra loro. Ad esempio, in inglese “sea” e “ocean” (cioè mare e oceano) risultano molto vicini (perché simili) nello spazio vettoriale degli embedding – segno che il modello li considera concetti affini. In pratica, l’embedding è come un’impronta numerica che cattura il senso di un token: è grazie a queste rappresentazioni che l’LLM può “ragionare” sulle parole in ingresso e trovare connessioni tra termini correlati.
Dentro la scatola nera: com’è fatto (e addestrato) un LLM
Abbiamo visto a grandi linee come un LLM genera testo. Ma com’è strutturato internamente questo “scrittore automatico”? La risposta breve: è una rete neurale enorme, con miliardi di connessioni, addestrata su quantità mastodontiche di dati testuali. Due ingredienti, scala e quantità, sono stati fondamentali per il salto di qualità di questi modelli negli ultimi anni.
- Dati in abbondanza (token): i Large Language Model vengono pre-addestrati leggendo praticamente tutto quello che trovano. Documenti pubblici, libri, articoli, pagine web, conversazioni di forum – un vero tesoro linguistico. Il modello “digerisce” questo corpus immenso imparando, tramite un lungo processo di ottimizzazione, a predire la parola successiva in ogni frase. Ad esempio, il modello GPT-3 di OpenAI (sviluppato nel 2020) è stato addestrato usando circa 300 miliardi di token, che corrispondono a circa 45–60 TB di dati testuali (sui modelli successivi non si hanno informazioni ma si ipotizza tra 1 e 5 trilioni di token). Durante il training, l’LLM macina questi testi miliardi di volte, aggiustando gradualmente i propri parametri per migliorare la capacità di indovinare le parole seguenti. Un token può essere una parola intera, una radice (es. scriv), una sillaba, o persino una singola lettera o segno di punteggiatura. Tutto dipende dal metodo di tokenizzazione scelto. La frase “Ciao, come stai ?” potrebbe diventare semplicisticamente →
["Ciao", ",", "come", "stai", "?"]→ 5 token. Ma i metodi sono i più disparati. Ad esempio la stessa frase ChatGPT la "tokenizza" ancora più finemente: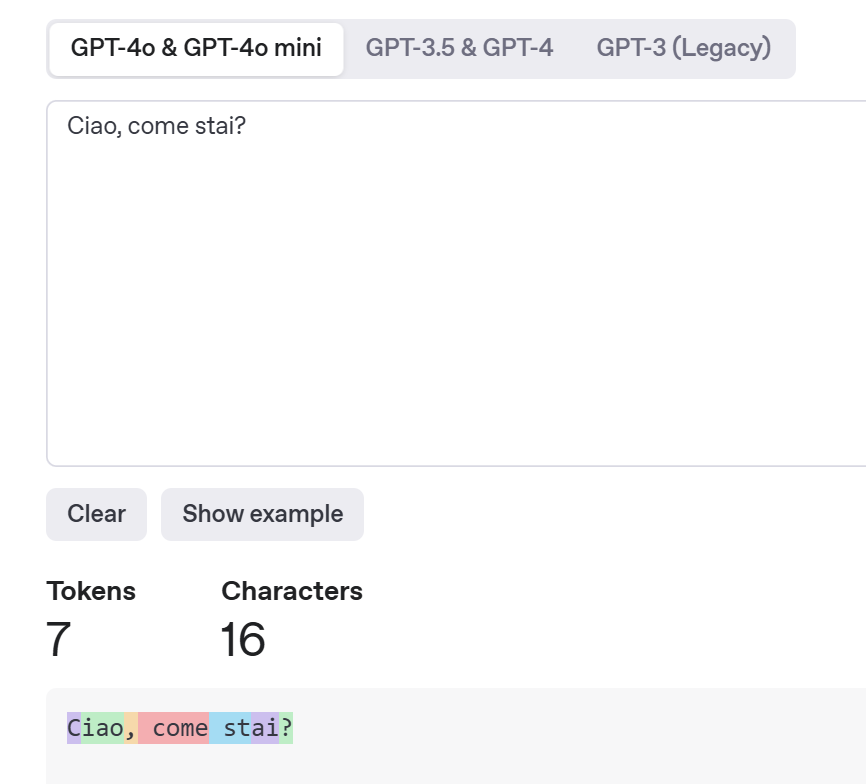
- Tanti parametri (il “cervello” della rete): se i token sono i pezzi di linguaggio, i parametri sono le connessioni apprese durante l’addestramento. I parametri di un modello sono i coefficienti numerici (pesi) che collegano i neuroni artificiali al suo interno. Ogni parametro è come una manopola o un interruttore che il modello può regolare mentre impara. Quando il modello è addestrato, queste “manopole” restano fisse e determinano come l’IA risponde. Più parametri ci sono, più capacità espressiva ha la rete neurale – in teoria – per cogliere sfumature e pattern del linguaggio. I moderni LLM sono giganteschi: GPT-3, ad esempio, ha 175 miliardi di parametri. Per dare un’idea, il suo predecessore GPT-2 ne aveva “solo” 1,5 miliardi. Questa crescita esponenziale ha permesso al modello di immagazzinare conoscenza linguistica molto più approfondita (anche se non organizzata come una conoscenza umana, ovviamente). Più neuroni e connessioni significano che il modello può rappresentare concetti molto complessi e variegati. Naturalmente addestrare modelli del genere richiede risorse computazionali enormi (supercomputer con migliaia di GPU che macinano dati per settimane), ma il risultato è un’IA capace di generare testi straordinariamente coerenti.
Immaginiamo che un LLM sia uno chef che scrive ricette:
I token sono gli ingredienti che lo chef usa (le parole da combinare).
I parametri sono le esperienze accumulate, le prove e gli errori che gli hanno insegnato a cucinare bene (cioè a generare testo sensato).
Più parametri = uno chef più esperto.
Più token = più ingredienti con cui preparare nuovi piatti.
A dare veramente il via a questa nuova generazione di IA linguistiche è stata però una svolta architetturale. Fino a qualche anno fa, i modelli di elaborazione del linguaggio (come i traduttori automatici o i vecchi chatbot) si basavano in gran parte su reti neurali ricorrenti o sequenziali, che leggevano il testo parola per parola in ordine. Nel 2017, un team di ricercatori di Google ha introdotto un modello diverso, chiamato Transformer (trasformatore), descrivendolo in un celebre paper scientifico dal titolo “Attention Is All You Need”. Questa architettura ha rivoluzionato il campo perché analizza una sequenza di testo in parallelo anziché in sequenza, usando un meccanismo di self-attention (auto-attenzione) che permette al modello di concentrarsi sui punti importanti di una frase ignorandone i dettagli meno rilevanti. In pratica il trasformatore guarda all’intera frase (o anche interi paragrafi) tutta in una volta, e per ogni parola capisce quali altre parole del contesto sono più utili per interpretarla. È un po’ quello che facciamo noi leggendo: se diciamo “il giovane drago imparò a volare”, il nostro cervello collega drago con volare e non dà peso a parole come il o a. Il Transformer permette all’LLM di fare lo stesso tipo di collegamenti in maniera efficiente e accurata.
Questa innovazione ha reso possibili modelli con contesti molto ampi (capaci di “ricordare” e tenere in considerazione molte frasi precedenti) e con output di qualità molto più alta. Non sorprende che tutti i principali LLM odierni – da GPT-3 e GPT-4 di OpenAI ai modelli di Google, Meta, Anthropic ecc. – siano basati su architettura transformer. Per chi volesse vedere con i propri occhi come funziona un trasformatore, il Financial Times ha pubblicato un bellissimo articolo interattivo (in inglese) che illustra passo passo questi meccanismi. Scorrendo quella pagina web speciale, è possibile visualizzare come un LLM codifica le parole, come l’attenzione evidenzia certe parole chiave, e persino come possono emergere fenomeni come le allucinazioni durante la generazione di testo. È un ottimo complemento visuale a quanto stiamo raccontando qui. (Curiosità: il nome stesso di ChatGPT descrive la sua genetica: GPT → Generative. Pretrained. Transformer).
LLM ≠ intelligenza umana: miti e realtà
Dopo tutto quello che abbiamo visto, potrebbe sorgere spontanea una domanda: ma dunque questi LLM sono davvero “intelligenti”? Dipende da cosa intendiamo per intelligente. Certo, sanno generare testo di senso compiuto, usare un lessico ricco, perfino imitare stili letterari. Tuttavia, non possiedono una comprensione profonda di ciò che scrivono, né coscienza o intenzionalità. Spesso attribuiamo loro caratteristiche umane (c’è chi chiede al chatbot se prova emozioni o se pensa come noi), ma è un’illusione. In realtà un LLM non “capisce” il significato come lo capiremmo noi, ma manipola simboli statistici. Alcuni ricercatori hanno icasticamente definito questi modelli “pappagalli stocastici”: in pratica, imitano il linguaggio umano senza averne la consapevolezza.
Conoscere la struttura e il metodo di generazione di un LLM ci aiuta a ridimensionare alcune aspettative e ad usarlo con maggiore senso critico. Ecco alcuni punti da tenere a mente quando interagiamo con queste IA:
- Non hanno vera comprensione o conoscenza – Un LLM non sa di cosa parla; mette insieme frasi basate sulle probabilità apprese. Può scrivere “Il Sole è una stella” perché ha visto spesso quella frase, ma non ha in testa un modello del sistema solare. Come detto, è un pappagallo statistico che ripete strutture linguistiche plausibili senza ancorarle a un significato vero. Dunque, anche se le sue risposte suonano competenti, l’LLM non dispone di un vero filtro di verità o di logica: sta solo seguendo i pattern appresi.
- Possono allucinare (inventare) fatti – Capita spesso che un LLM fornisca informazioni del tutto sbagliate con tono sicuro. Ad esempio, potrebbe affermare una data storica errata, citare una legge inesistente o mischiare biografie di persone diverse. Questo avviene perché il modello non ha modo di verificare le sue affermazioni: se certi termini compaiono frequentemente insieme nei suoi dati di training, lui li userà, anche se l’informazione è falsa. In gergo si parla di allucinazioni dell’IA. Il problema è che l’LLM non sa di non sapere: non ha un feedback interno che gli dica “questa cosa è sbagliata”. Un gruppo di esperti ha sottolineato proprio che, “siccome si limita a mettere insieme parole in base ai dati di addestramento, un LLM non si rende conto se sta dicendo qualcosa di scorretto o inopportuno”. Sta a noi utenti, quindi, fare da filtro: mai prendere per oro colato tutto ciò che esce da ChatGPT & co., specialmente dati di fatto importanti, senza una verifica esterna.
- Hanno i bias dei dati (e dei programmatori) – Un LLM assorbe pregiudizi, errori e punti di vista presenti nei testi con cui è stato addestrato. Se gran parte del web contiene un bias (ad esempio stereotipi di genere o discriminazioni razziali), il modello può rifletterli nelle sue risposte. E anche se ci sono processi di correzione e filtraggio, non esiste garanzia assoluta di neutralità o accuratezza. In più, i valori che guidano il modello (cosa considera accettabile o meno dire) dipendono in larga misura da scelte dei suoi sviluppatori durante la fase di fine-tuning. Questo non significa che l’LLM sia “malvagio” o manipolatore di per sé – ricordiamo, non ha volontà – ma che può ereditare sia il meglio sia il peggio del materiale su cui è stato addestrato.
- Non provano emozioni (anche se le simulano) – Gli LLM possono scrivere frasi molto empatiche (“Mi dispiace che tu stia attraversando questo momento difficile…”), ma ciò non implica alcuna esperienza emotiva da parte loro. Quando leggiamo una risposta accorata di un chatbot, siamo tentati di attribuirle un’intenzione o una sensibilità; in realtà il modello sta semplicemente riproducendo schemi linguistici tipici delle conversazioni empatiche che ha visto nei suoi dati. Non c’è un “io” dietro quelle parole, nessuna coscienza che soffre, gode o tiene davvero a noi. È fondamentale ricordarlo per evitare di prendere decisioni emotive basate su una falsa percezione dell’IA (ad esempio, sentirsi giudicati da lei, o credere che “ci tenga” davvero). L’LLM è abile imitazione di un parlante umano, ma resta un’imitazione.
Conoscere come è fatto e come lavora un Large Language Model ci aiuta a usarlo in modo più maturo e consapevole. Possiamo ammirarne le capacità – perché è straordinario che un software autocompleti testi così bene da sembrare creativi o competenti – senza però mitizzarlo. Un LLM non è un oracolo infallibile né una mente artificiale dotata di saggezza propria: è un potente strumento statistico, un prodotto dell’ingegno umano (ricerca, algoritmi e tonnellate di dati). Sta a noi utilizzarlo come amplificatore della nostra creatività e produttività, ma anche come soggetto da monitorare. In fondo, dietro le quinte di un’IA linguistica non c’è magia – c’è matematica, informatica e tanta probabilità. E più ne siamo consapevoli, meglio potremo sfruttare queste nuove tecnologie senza farci sfruttare da esse.
Da dove arrivano i dati? (Spoiler: anche da te)
Immagina per un attimo un’IA come un grande scrittore che non ha mai vissuto nulla in prima persona. Non ha viaggiato, non ha amato, non ha mai mangiato una pizza vera. Eppure scrive poesie, articoli, dialoghi brillanti. Come fa? Semplice: legge tutto quello che trova. Interi oceani di parole – siti web, manuali, romanzi, ricette, forum, tweet, commenti, newsletter, persino battute da meme e recensioni su Amazon. Se c’è stato un momento in cui hai pubblicato qualcosa online, c’è una buona possibilità che l’IA lo abbia letto (o almeno scannerizzato) in silenzio.
Ma ecco il punto critico: per anni si è attinto a piene mani da Internet – tutto a portata di clic. Il problema è che molti di quei contenuti sono protetti da copyright: libri, articoli, blog, canzoni, manuali. E non sempre chi li ha scritti ha dato il permesso di usarli. Negli Stati Uniti, diversi autori, editori e giornalisti hanno fatto causa a colossi come OpenAI e Meta, accusandoli di aver "ingurgitato" opere intere senza autorizzazione per addestrare i loro modelli. Le aziende, dal canto loro, si difendono invocando il “fair use”, una clausola del diritto americano che permette l’uso di opere protette in certi casi (come ricerca o parodia). Ma il confine tra uso lecito e sfruttamento improprio è sempre più sottile, specialmente se l’output dell’IA finisce per somigliare troppo a un contenuto originale. In Europa, intanto, si spingono nuove regole per obbligare le aziende a dichiarare chiaramente che dati usano, dove li prendono e per che cosa. Insomma, si sta cercando di trasformare la scatola nera dei LLM in una finestra (almeno socchiusa) sulla loro memoria. E non è una battaglia da poco: in gioco non c’è solo la proprietà intellettuale, ma il diritto delle persone a sapere se – e come – i loro contenuti vengono usati per creare “l’intelligenza” delle macchine.
Ultimamente, parlare di come vengono “allenate” le intelligenze artificiali significa entrare in una cucina in pieno fermento. Gli ingredienti sono testi presi dal web, grandi banche dati, righe di codice, dati artificiali creati da altre IA, e – sempre più spesso – un pizzico di controversia legale. Le grandi aziende del settore lavorano costantemente per rendere questi modelli più performanti, più affidabili, più “umani” nel modo di rispondere. Ma non si tratta solo di potenza di calcolo: il vero salto lo stanno facendo con tecniche di fine-tuning mirato e dati sintetici. Detto in modo semplice, si prendono modelli generici e li si “riprogramma” su settori specifici – medicina, giurisprudenza, creatività – usando dati nuovi, a volte prodotti proprio da un’altra IA. Un po’ come allenare un buon musicista a specializzarsi nel jazz, dopo anni di classica. Si aggiungono e affiancano anche altre tecniche prima di arrivare alla risposta vera e propria come ad esempio il Reinforcement Learning from Human Feedback: sì, l’IA viene corretta anche a mano da persone in carne e ossa, che le dicono cosa suona naturale, cosa è fuori luogo, cosa è utile (avete presente quel pollice su/giù che compare alla fine in ogni risposta?). E questo, strano a dirsi, è ciò che la rende un po’ meno “macchina” e un po’ più “dialogante”.
LLM con le mani: la nuova generazione di IA che pensa e agisce
L’IA oggi non si accontenta più di rispondere a una domanda: vuole (o meglio, può) agire. Stiamo assistendo a un passaggio cruciale, quello dagli LLM tradizionali – che producono qualcosa e si fermano lì – a sistemi agentici, cioè agenti digitali capaci di compiere azioni complesse, in autonomia, su più passaggi. Sembra fantascienza, ma non lo è. Immagina di chiedere a un’IA: “Prenotami un viaggio per Roma a ottobre, con hotel vicino al centro e voli in orari comodi.” Fino a poco fa avresti ricevuto un elenco di opzioni. Oggi, un agente IA come quelli su cui stanno lavorando OpenAI, Google o Meta può effettivamente aprire siti, cercare voli e hotel, confrontare prezzi, compilare moduli, e – in certi casi – completare il tutto. Può interagire direttamente e in modo autonomo con piattaforme e servizi di terze parti. Il tutto seguendo una logica propria, imparata in fase di addestramento, pre-allenata dal fornitore dello strumento e senza che tu debba intervenire di continuo. E non parliamo più solo di esperimenti in laboratorio: OpenAI, ad esempio, ha presentato “Operator”, un prototipo capace di usare un computer virtuale come farebbe un utente umano, con tanto di mouse e tastiera simulati. È stato addestrato non solo a generare testo, ma a capire cosa fare in contesti digitali complessi, adattandosi passo dopo passo. La novità? Questi agenti non sono più solo bravi a scrivere, produrre immagini, audio o video – stanno diventando capaci di comprendere il contesto e portare a termine task pratici. E, se tutto funziona come sperano le big tech, potremmo presto avere agenti personali evoluti che ci gestiscono email, documenti, viaggi e appuntamenti o interi flussi di attività complesse.
Ma, ovviamente, qui iniziano anche le domande spinose, per ora ce ne poniamo solo qualcuna dato che la lista potrebbe essere molto più ricca:
- Quanto possiamo fidarci di un software che agisce al posto nostro?
- Abbiamo davvero controllo su ciò che l’agente fa quando agisce “da solo”?
- E come assicurarci che faccia davvero ciò che vogliamo – e non altro?
- Chi è responsabile se un agente IA prende una decisione sbagliata o dannosa?
- Chi controlla i filtri, i limiti e le “zone cieche” dell’agente IA?
- Quanto è accettabile – eticamente e culturalmente – permettere che un software “parli e agisca per noi”?
- Soprattutto nei contesti educativi, professionali o affettivi: vogliamo che le nostre parole siano le nostre, o solo le più efficienti?
Questo post è parte della rubrica TrAIettorie di cui potete trovare l'indice completo qui.